容器技术
ubuntu使用APT安装docker并指定版本
Helm部署与使用
Helm常用命令
从Helm仓库创建应用流程示例
Helm部署与使用
K8S中部署mysql-ha高可用集群
helm启动mysql-ha
helm几个常用仓库
Kubernetes使用helm部署Mysql-Ha
k8s入门:Helm 构建 MySQL
docker批量修改tag(批量push)
k8s之yaml文件详解
将 MySQL 通过 bitpoke/mysql-operator 部署到 k8s 内部
k8s pvc扩容:pvc创建后扩容
K8S性能分析
部署Metrics Server
Kubernetes集群搭建
kubespray 部署常见问题和优化汇总
kubernetes-sigs/kubespray at release-2.15
K8S-pod配置文件详解
KubeSphere知识库
在 Kubernetes 上最小化安装 KubeSphere
卸载 KubeSphere 和 Kubernetes
KubeSphere 应用商店
修改pod中容器的时区
k8s之Pod安全策略
Harbor 登陆失败,用户名或者密码不正确。405 Not Allowed
Docker-leanote_n1
kubesphere/kubekey
Kubernetes Static Pod (静态Pod)
kubernets kube-proxy的代理 iptables和ipvs - 30岁再次出发 - 博客园
k8s生产实践之获取客户端真实IP - SSgeek - 博客园
kube-proxy ip-tables故障解决
k8s入门:Helm 构建 MySQL
docker批量修改tag(批量push)
prometheus operator 监控redis-exporter
Helm3 安装 ElasticSearch & Kibana 7.x 版本
kubernete强力删除namespace_redis删除namespace命令
EFK (Elasticsearch + Fluentd + Kibana) 日志分析系统
k8s日志收集实战(无坑)
fluentd收集k8s集群pod日志
Elasticsearch+Fluentd+Kibana 日志收集系统的搭建
TKE/EKS之configmap,secret只读挂载
K8s基于Reloader的ConfigMap/Secret热更新
使用 Reloader 实现热部署_k8s reloader
k8s使用Reloader实现更新configmap后自动重启pod
在 Kubernetes 上对 gRPC 服务器进行健康检查 | Kubernetes
Kubernetes ( k8s ) gRPC服务 健康检查 ( livenessProbe ) 与 就绪检查 ( readinessProbe )
排查kubernetes中高磁盘占用pod
helm 安装 MongoDB 集群
helm 安装 Redis 1 主 2 从 3哨兵
【k8s】使用 Reloader 实现热部署
k8s证书过期,更新后kubelet启动失败
kubeadm证书/etcd证书过期处理
三种监控 Kubernetes 集群证书过期方案
K8s 集群(kubeadm) CA 证书过期解决方案
k8s调度、污点、容忍、不可调度、排水、数据卷挂载
5分钟搞懂K8S的污点和容忍度(理论+实战)
Kubernetes进阶-8基于Istio实现微服务治理
macvlan案例配置
快速解决Dockerhub镜像站无法访问问题
info_scan开源漏洞扫描主系统部署
本文档使用 MrDoc 发布
-
+
首页
将 MySQL 通过 bitpoke/mysql-operator 部署到 k8s 内部
目前 openbayes 的几乎所有组件都部署在 k8s 内部,但 mysql 作为核心的数据存储节点对其要求都蛮高的,通常来说是需要独立部署的,对于目前的业务场景,其要求主要包含以下几点: 1. 需要持久化存储,一旦数据丢失问题非常严重 2. 对性能有要求,不然会拖垮依赖它的一切服务 3. 需要一些额外的备份机制,可以快速的从一个备份做恢复 4. 需要对应的监控体系 5. mysql 需要可以比较容易的通过各种客户端访问,方便不同的角色对数据做分析或者做 debug 6. _在规模比较大的时候可能会做读写分离_ 之所以希望将 mysql 部署到 k8s 内主要还是希望达到以下目的: 1. 减少外部依赖,支持更广泛部署场景;目前对于一些环境是使用了云服务商所提供的数据库(aws / ucloud),然而并不是所有的情况都能这么做。 2. 统一部署模式,降低部署门槛;对于无法使用云服务商的数据库的场景,通常需要独立在某一台机器上安装 mysql 但这个部署模式与 k8s 是分离的,相当于多了一部分手工部署的工作量,而且手动部署也很难满足以上的几点要求的,自动化越少,部署门槛就会越高。 openbayes 本身对数据库性能的要求没有那么高,用户的大量数据是以分布式存储的形式保存的,mysql 的负载通常不高,这也让 mysql 部署在 k8s 里成为了可能。 下面介绍 bitpoke/mysql-operator 如何满足上述要求。 ## 基本介绍 在使用云服务商的数据库的时候我就在想,如果能有一套 k8s 的 operator 能够支持快速部署 / 数据库配置 / 周期性备份 / prometheus 指标暴露就好了,在做了简单的搜索后还真的发现了这么个东西 [bitpoke/mysql-operator](https://github.com/bitpoke/mysql-operator) ,满足了说所提及的这一切: 1. 内置了 mysql 部署配置,简单修改配置可以实现将 mysql 的存储放置在 hostPath 或者指定的 storageClass 解决了持久化存储的问题 2. 既然可以指定具体部署的存储,那么也能指定 mysql 部署的节点,性能的问题基本得到解决 3. 内置 extraBackup 支持手动或者 cronjob 周期性备份数据库到指定的对象存储 4. 部署起来的 mysql 自带 exporter 可以直接和 prometheus 对接,然后把数据通过 grafana 展示,监控 / 告警也就有了 5. 通过配置额外的 nodePort 类型的 Service 可以将 mysql 服务暴露出来,外部访问的问题就解决了 6. 这个 operator 本身就支持读写分离,不过我并没测试 https://github.com/bitpoke/mysql-operator/blob/master/deploy/charts/mysql-operator/values.yaml 这是 helm charts 的 values.yaml 把这个文件下载到本地,按照具体环境做一定修改后执行以下命令即可部署 operator 了: ``` # 这里用的是 helm3 helm repo add bitpoke https://helm-charts.bitpoke.io helm install mysql-operator bitpoke/mysql-operator \ -f values.yaml \ -n infra --create-namespace ``` 其中 `values.yaml` 需要修改的部分主要就是两部分: 1. 镜像位置(image sidecarImage orchestrator.image),国内部署速度不太行,建议自行拉到访问比较好的国内节点 2. 存储,默认 `persistence.enabled: false` 可以按照自己的情况做修改,这里只支持 `storageClass` 的方式 部署好之后才是第一步,即成功部署了 `operator` 本身,下面就是具体部署一个 `mysql` 了,在 https://github.com/bitpoke/mysql-operator/tree/master/examples 有一个例子,可以看到 mysql 被定义为了一个叫做 `MysqlCluster` 的 CRD。主要需要修改的部分有以下: 1. `secretName` 见 https://github.com/bitpoke/mysql-operator/blob/master/examples/example-cluster-secret.yaml 指初始化的一些数据,如 root 密码,数据库名称,用户名,用户密码 2. `image` / `mysqlVersion` mysql 的镜像,同样推荐修改为国内的镜像,具体版本也依照实际情况 3. `backupSchedule` 如果设置则是需要周期性备份,数据会按照该配置定期备份到指定的对象存储中,当然 `backupSecretName` 也需要配置正确才能使用 4. `mysqlConf` 对应 mysql.cnf 中的字段,依据自己需求配置 5. `volumeSpec` 数据持久化方式,和上文中 `operator` 的类似,但是更灵活,支持 hostPath 6. `initFileExtraSQL` 感觉这个 MysqlCluster 是希望用户每个数据库建立一个独立的资源,但是 openbayes 这里有一些附属数据库如果分开放置感觉有点没必要,所以这里就采用这个机制同时初始化了其他的数据库 ``` initFileExtraSQL: - "CREATE DATABASE IF NOT EXISTS `<otherdb>`" - "DROP USER IF EXISTS <otheruser>@'%'" - "CREATE USER <otheruser>@'%' IDENTIFIED BY '<PASSOWRD>'" - "GRANT ALL PRIVILEGES ON <otherdb>.* TO <otheruser>@'%'" - "FLUSH PRIVILEGES" ``` 注意这里有个奇怪的写法是需要先去 `DROP USER`… 至于为啥我并不知道,我只知道不这么做就是会报错… ## 备份 / 恢复 如上文所述,这个 `MysqlCluster` 支持自动的备份,当然也支持主动的备份,具体的文档在[Cluster Backups and Recovery](https://www.bitpoke.io/docs/mysql-operator/backups/)。 既然支持备份也支持恢复,具体的文档在也在[Cluster Backups and Recovery](https://www.bitpoke.io/docs/mysql-operator/backups/)。 这些步骤我都测试过了,确认可以走的通的。以及这个备份的功能已经非常体贴了: 1. 支持手动备份通过 cron 控制 2. 支持保存最近的 N 个版本 3. 恢复只需要在初始 mysql 时填写 s3 路径即可 在备份到 s3 不成功可以看看具体的报错信息,它具体备份采用的是 rclone 这个工具。不成功基本就是两个方向: 1. s3 设置有问题,上传直接挂了 2. 你所使用的对象存储可能不是 rclone 会完全支持的,这种情况比较少见,但是我确实踩到了,具体来讲就是 ucloud 之前缺乏某些操作的支持,但是目前已经支持了呢 ## 监控 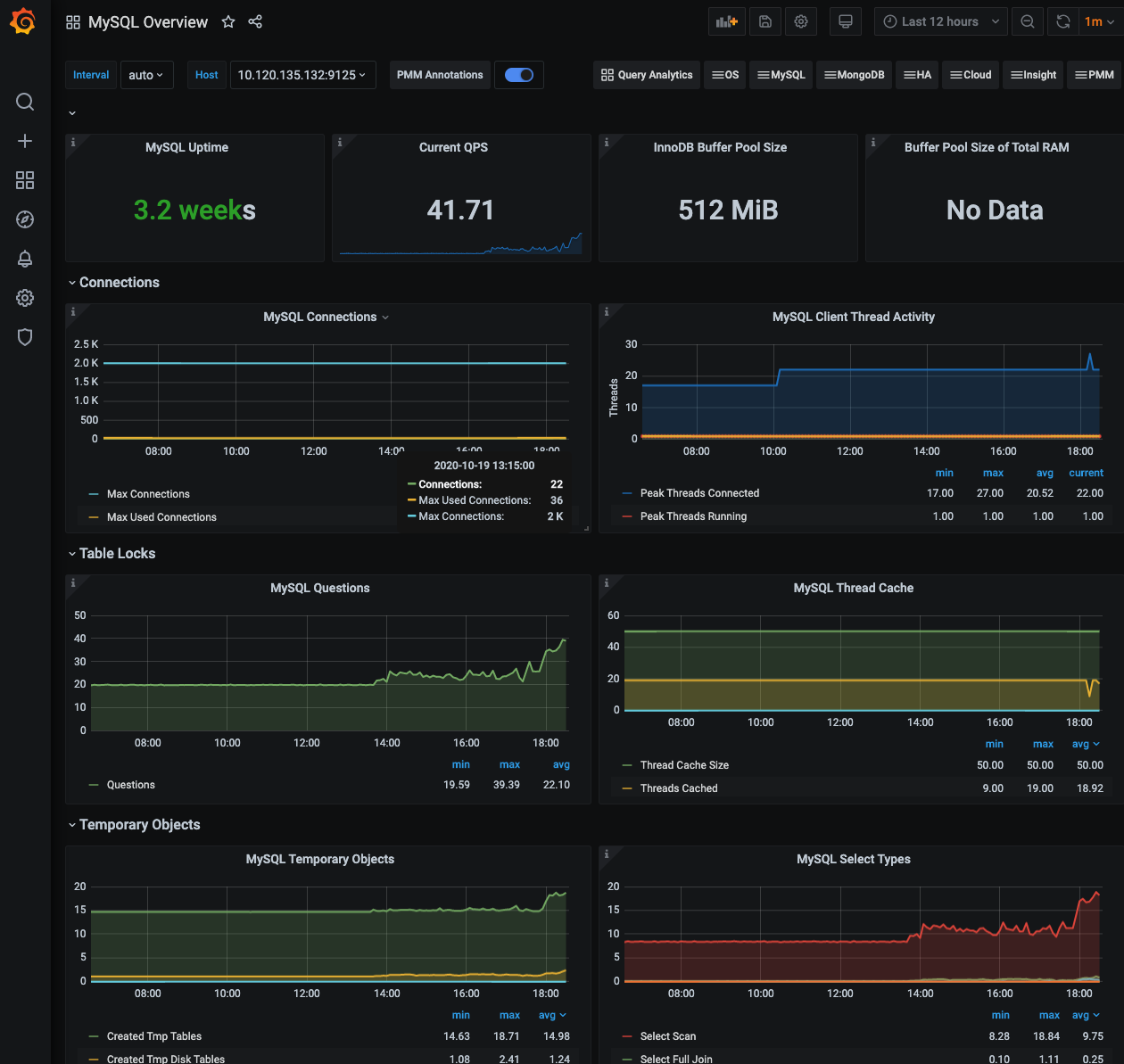 如上图所示,这是我直接将 https://grafana.com/grafana/dashboards/7362 这个仪表盘导入所看到的效果。 ## 外部访问 增加一个额外的 NodePort 即可: ``` apiVersion: v1 kind: Service metadata: name: local-openbayes-mysql-nodeport-master spec: ports: - name: mysql port: 3306 protocol: TCP targetPort: 3306 nodePort: 30016 selector: app.kubernetes.io/managed-by: mysql.bitpoke.org app.kubernetes.io/name: mysql mysql.bitpoke.org/cluster: <local-openbayes> role: master type: NodePort ``` ## 独立 io 在使用的过程中遇到一个特殊的情况,mysql 如果和其他的服务共用一个 storageClass 可能会出现 io 抢占的情况,导致 mysql 的延迟非常巨大。目前 k8s 还没有一个很好的办法解决这个问题。唯一想到的就是为 mysql 分配一套单独的 storageClass(比如 [local storage path](https://github.com/rancher/local-path-provisioner) 的方案)。
adouk
2023年1月20日 09:01
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码