容器技术
ubuntu使用APT安装docker并指定版本
Helm部署与使用
Helm常用命令
从Helm仓库创建应用流程示例
Helm部署与使用
K8S中部署mysql-ha高可用集群
helm启动mysql-ha
helm几个常用仓库
Kubernetes使用helm部署Mysql-Ha
k8s入门:Helm 构建 MySQL
docker批量修改tag(批量push)
k8s之yaml文件详解
将 MySQL 通过 bitpoke/mysql-operator 部署到 k8s 内部
k8s pvc扩容:pvc创建后扩容
K8S性能分析
部署Metrics Server
Kubernetes集群搭建
kubespray 部署常见问题和优化汇总
kubernetes-sigs/kubespray at release-2.15
K8S-pod配置文件详解
KubeSphere知识库
在 Kubernetes 上最小化安装 KubeSphere
卸载 KubeSphere 和 Kubernetes
KubeSphere 应用商店
修改pod中容器的时区
k8s之Pod安全策略
Harbor 登陆失败,用户名或者密码不正确。405 Not Allowed
Docker-leanote_n1
kubesphere/kubekey
Kubernetes Static Pod (静态Pod)
kubernets kube-proxy的代理 iptables和ipvs - 30岁再次出发 - 博客园
k8s生产实践之获取客户端真实IP - SSgeek - 博客园
kube-proxy ip-tables故障解决
k8s入门:Helm 构建 MySQL
docker批量修改tag(批量push)
prometheus operator 监控redis-exporter
Helm3 安装 ElasticSearch & Kibana 7.x 版本
kubernete强力删除namespace_redis删除namespace命令
EFK (Elasticsearch + Fluentd + Kibana) 日志分析系统
k8s日志收集实战(无坑)
fluentd收集k8s集群pod日志
Elasticsearch+Fluentd+Kibana 日志收集系统的搭建
TKE/EKS之configmap,secret只读挂载
K8s基于Reloader的ConfigMap/Secret热更新
使用 Reloader 实现热部署_k8s reloader
k8s使用Reloader实现更新configmap后自动重启pod
在 Kubernetes 上对 gRPC 服务器进行健康检查 | Kubernetes
Kubernetes ( k8s ) gRPC服务 健康检查 ( livenessProbe ) 与 就绪检查 ( readinessProbe )
排查kubernetes中高磁盘占用pod
helm 安装 MongoDB 集群
helm 安装 Redis 1 主 2 从 3哨兵
【k8s】使用 Reloader 实现热部署
k8s证书过期,更新后kubelet启动失败
kubeadm证书/etcd证书过期处理
三种监控 Kubernetes 集群证书过期方案
K8s 集群(kubeadm) CA 证书过期解决方案
k8s调度、污点、容忍、不可调度、排水、数据卷挂载
5分钟搞懂K8S的污点和容忍度(理论+实战)
Kubernetes进阶-8基于Istio实现微服务治理
macvlan案例配置
快速解决Dockerhub镜像站无法访问问题
info_scan开源漏洞扫描主系统部署
本文档使用 MrDoc 发布
-
+
首页
k8s调度、污点、容忍、不可调度、排水、数据卷挂载
[K8S](https://so.csdn.net/so/search?q=K8S&spm=1001.2101.3001.7020)集群中,通过List-watch机制进行每个组件的协作,保持数据同步。这种设计可以实现每个组件之间的解耦 kubectl配置文件,统一向集群内部apiserver发送命令——通过apiserver把命令发送到各个组件 创建成功之后,kubectl get pod,kubectl describe pod nginx查看信息——在ETCD数据库中 List-watch会在每一步把监听的消息(apiserver:6443)——组件controller-manager、schedule、kubelet、ETCD都会监听apiserver的6443端口 ##### ****2、创建pod的过程:**** 1、客户端向apiserver发送创建创建pod的请求,然后apiserver将请求信息存入到ETCD中 2、存入完之后,ETCD会通过apiserver发送创建pod资源的事件 3、controller-manager通过List-watch机制监听apiserver发送出来的事件,并创建相关的pod资源。创建完成之后,通过apiserver将信息存入到ETCD中 4、ETCD存入更新信息之后,再次通过apiserver发送调度pod资源的事件到scheduler 5、scheduler通过List-watch机制监听到apiserver发出的调度事件,通过调度算法,将pod资源调度到合适的node节点上,调度完成后通过apiserver将调度信息更新到ETCD中 6、ETCD收到更新信息后,再次向apiserver发出的创建pod的事件 7、kubelet通过List-watch机制监听apiserver发出的创建pod的事件,然后根据事件信息,在相应的node节点完成pod的创建 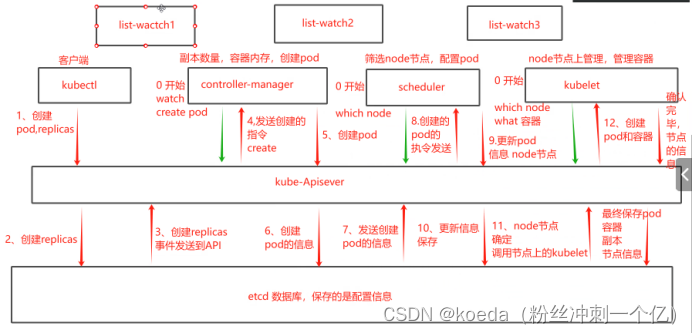 ****二、scheduler调度的过程和策略:**** ##### ****1、简介**** scheduler是K8S集群的调度器,把pod分配到集群的节点 调度规则: 1. 公平,每个节点都能够分配资源 2. 资源高效利用,集群中的资源可以被最大化使用 3. 效率:调度的性能要好,能够尽快的完成大批量pod的调度工作 4. 灵活:允许用户根据自己的需求,控制和改变调度的逻辑 scheduler:负责调度资源,把Pod调度到node节点上 有两种策略:预算策略、优选策略 scheduler是一个单独运行的程序,只要启动之后就会一直监听apiserver。获取报文中的字段:spec中的nodeName字段 创建pod时,为每个pod创建一个binding,表示该往哪个节点上部署 创建pod到节点时,有两个策略 先执行预算策略,在执行优先策略。这两步的操作都必须成功,否则立刻返回报错 部署的node必须满足这两个策略,少一个都不行 ##### ****2、预算策略:predicate**** 自带一些算法,选择node节点,是scheduler自带的算法策略,不需要人工干预 1. podfitsresources:pod的适应策源,检查节点上剩余的资源是否满足pod请求的资源(主要是CPU和内存) 2. podfitshost:po适应主机,如果pod指定了node的name,检测主机名是否存在,如果存在要和pod指定的名称匹配,这才能调度过去 3. podselectormarches:pod选择器匹配,创建pod的时候,可以根据node'节点的标签来进行匹配。他查找指定的node节点上标签是否存在。存在的标签是否匹配 4. nodeskconflict:无磁盘冲突,确保已挂载的卷和pod卷不发生冲突。除非目录是只读 如果预算策略不满足,pod将始终处于pending状态,不断重试调度,直到节点满足条件为止 若三个node节点都满足——>优选策略 ##### 3、优先策略: ###### 3.1、leastrequestedpriority: 最低请求优先级,通过算法计算节点上的CPU和内存使用率,确定节点的权重 使用率越低的节点,相应的权重就越高。调度时会更倾向于这些使用率低的节点。实现资源合理的利用 ###### 3.2、balanceresourceallocation: 平衡资源分配,算CPU和内存的使用率,给节点赋予权重。权重算的是CPU和内存使用率接近,权重越高。 和上面的最低请求优先级一起使用 举例: node1 CPU和内存使用率:20 60 node2 CPU和内存使用率:50 50 node2的内存和CPU使用率接近,权重高,会被选择 ###### 3.3、imagelocalitypriority: 节点上是否已经有了要部署的镜像。镜像的总数成正比,满足的镜像数越多,权重越好 以上三个策略都是scheduler自带的算法,自动的 ##### 4、选择的过程: 先通过预算策略选择出可以部署的节点,在通过优选策略选择出最好的节点,以上都是自带的算法。K8S集群自己来选择 #### 三、kubernetes对Pod的[调度策略](https://so.csdn.net/so/search?q=%E8%B0%83%E5%BA%A6%E7%AD%96%E7%95%A5&spm=1001.2101.3001.7020) 在 Kubernetes 中,调度 是指将 Pod 放置到合适的节点上,以便对应节点上的 Kubelet 能够运行这些 Pod。 1)定向调度: 使用 nodeName 字段指定node节点名称;使用 nodeSelector 字段指定node节点的标签; 2)亲和性调度: 使用 节点/Pod 亲和性(NodeAffinity、PodAffinity、PodAntiAffinity); 3)污点与容忍: 使用 节点设置污点,结合 Pod设置容忍。 4)全自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出; 1. `#补充,Pod和node的关系` 2. `Node 是 Kubernetes 集群中的工作节点` 3. `一个 Node 可以运行多个 Pod,而一个 Pod 只能运行在一个 Node 上` 4. `使用标签和选择器可以管理 Node 和 Pod 之间的关系,从而实现灵活的调度和管理。` #### 四、定向调度 ##### 1、调度策略简介: nodeName:指定节点名称,用于将Pod调度到指定的Node上,不经过调度器。 nodeSelector:在 Pod 定义文件的 spec 下的 nodeSelector 字段中设置一个标签选择器,在 Pod 调度的时候,只有具有这些标签的 Node 才会被考虑用来运行这个 Pod。 ##### ****2、指定节点:**** spec参数设置: nodeName: node2 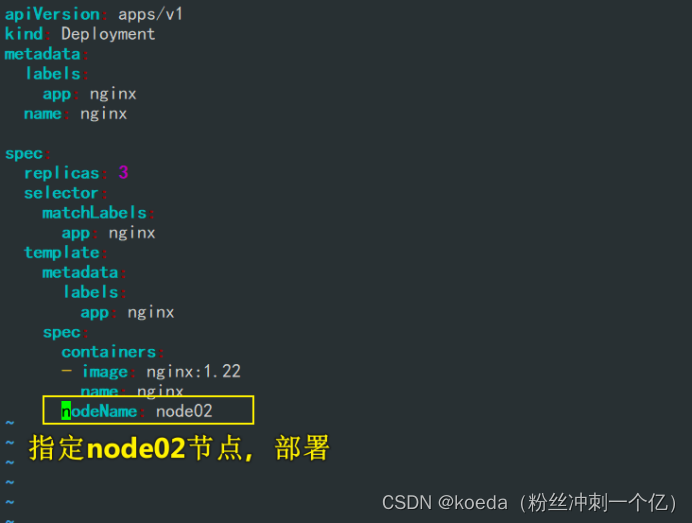 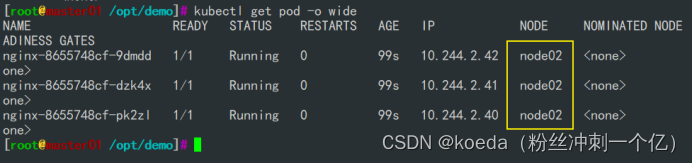  指定了节点,在参数中设置了nodeName,指定了节点的名称,会跳过scheduler的调度策略,这个规则是强制匹配 ##### ****3、指定标签:**** spec参数设置: nodeSelector: 节点自定义标签: 1. `kubectl label nodes master01 test1=a` 2. `kubectl label nodes node01 test2=b` 3. `kubectl label nodes node02 test3=c` 6. `kubectl get nodes --show-labels` 7. `#查看节点的标签`   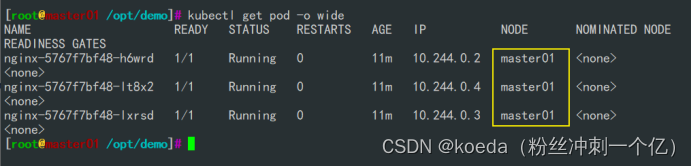 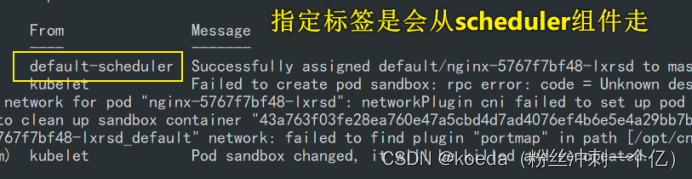 指定节点标签部署pod,是要经过scheduler的算法,如果节点不满足条件,pod会进入pending状态。直到节点满足条件为止 #### ****五、亲和性调度:**** ##### ****1、介绍:**** 两种亲和性:节点亲和性和pod亲和性 两种策略:软策略和硬策略 ****node节点的亲和性:**** preferredDuringSchedulingIgnoredDuringExecution:软策略 选择node节点时,声明了我最好能部署在node01。如果是软策略,他会尽量满足这个条件,不一定会完全部署在node01节点上。 requiredDuringSchedulinglgnoredDuringExecution:硬策略 选择pod时,声明了部署在node1上。如果是硬策略,必须满足硬策略的条件,必须部署在node1上。强制性要求 ****pod的亲和性:**** preferredDuringSchedulingIgnoredDuringExecution:软策略 要求调度器将pod调度到其他pod的亲和性匹配的节点上。可以是,也可以不是,尽量满足 requiredDuringSchedulingIgnoredDuringExecution:硬策略 要求调度器将pod调度到其他pod的亲和性匹配的节点上,强制性满足 ##### ****2、键值的运算关系:**** 都是根据标签来选择node或者pod的亲和性 1. In(大写的i):在,选择的标签值在node节点上存在 2. Notin:不在,选择label的值不在node节点上 3. Gt:大于,要大于选择的标签值,只能比较整数 4. Lt:小于,要小于选择的标签值,只能比较整数 5. Exists:存在,只是选择标签对象,不考虑值 6. DoesNotExist:不存在,选择不具有指定标签的对象。不考虑值 ##### 3、node亲和性实例 ****node亲和性的硬策略:**** ****in策略:**** 1. `apiVersion: apps/v1` 2. `kind: Deployment` 3. `metadata:` 4. `labels:` 5. `app: nginx` 6. `name: nginx` 8. `spec:` 9. `replicas: 3` 10. `selector:` 11. `matchLabels:` 12. `app: nginx` 13. `template:` 14. `metadata:` 15. `labels:` 16. `app: nginx` 17. `spec:` 18. `containers:` 19. `- image: nginx:1.22` 20. `name: nginx` 21. `affinity:` 22. `#选择亲和性部署方式` 23. `nodeAffinity:` 24. `#选择的是node节点的亲和性` 25. `requiredDuringSchedulingIgnoredDuringExecution:` 26. `nodeSelectorTerms:` 27. `#选择了亲和性的策略。nodeSelectorTerms你要选择哪个node作为硬策略。匹配的节点标签` 28. `- matchExpressions:` 29. `#定义了一个符合我要选择的node节点信息` 30. `- key: test3` 31. `operator: In` 32. `#指定键值对的算法` 33. `values:` 34. `- c` 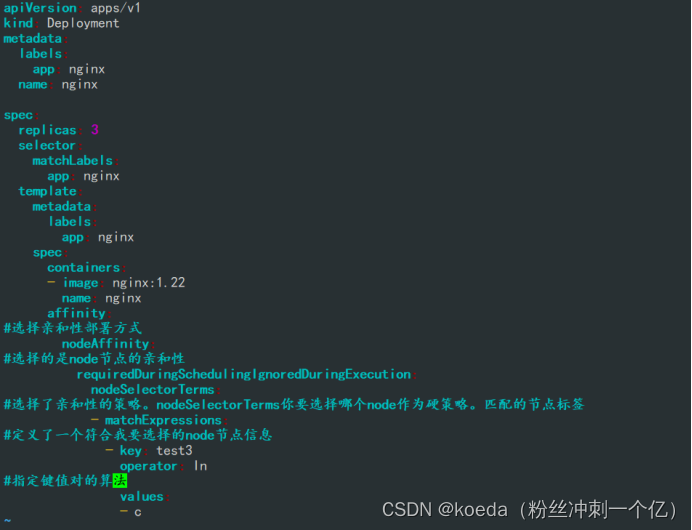 硬限制选择test3=c的节点 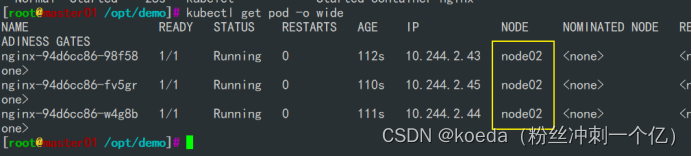 ****Notin:**** 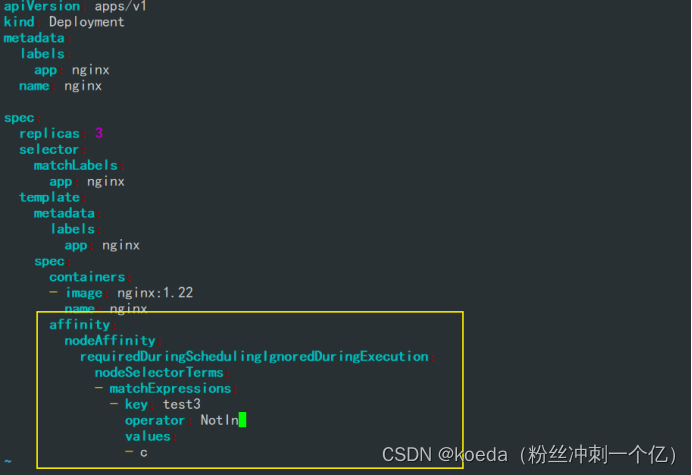 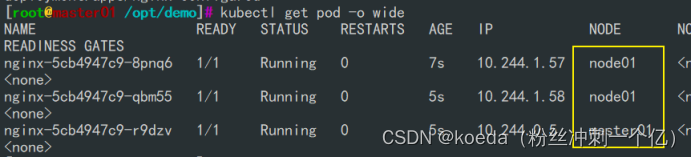 notin,只要不在test3=c的节点,都能够部署 删除节点上的标签: 1. `kubectl label nodes master01 test1-` 2. `kubectl label nodes node01 test2-` 3. `kubectl label nodes node02 test3-` 更改标签名: ``` kubectl label nodes node02 memory=1000 --overwrite ``` ****Gt:**** 1. `affinity:` 2. `nodeAffinity:` 3. `requiredDuringSchedulingIgnoredDuringExecution:` 4. `nodeSelectorTerms:` 5. `- matchExpressions:` 6. `- key: memory` 7. `operator: Gt` 8. `values:` 9. `- "612"` 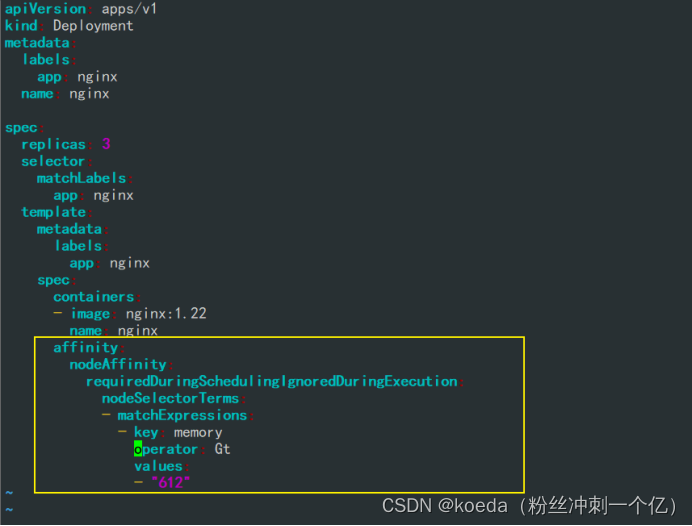 大于612节点上部署 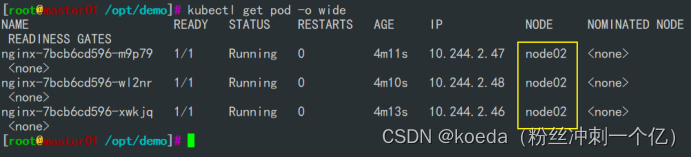 ****Exists:**** 1. `affinity:` 2. `nodeAffinity:` 3. `requiredDuringSchedulingIgnoredDuringExecution:` 4. `nodeSelectorTerms:` 5. `- matchExpressions:` 6. `- key: memory` 7. `operator: Exists` 8. `#指定键值对的算法为Exists或DoesNotExist,不能使用values字段` 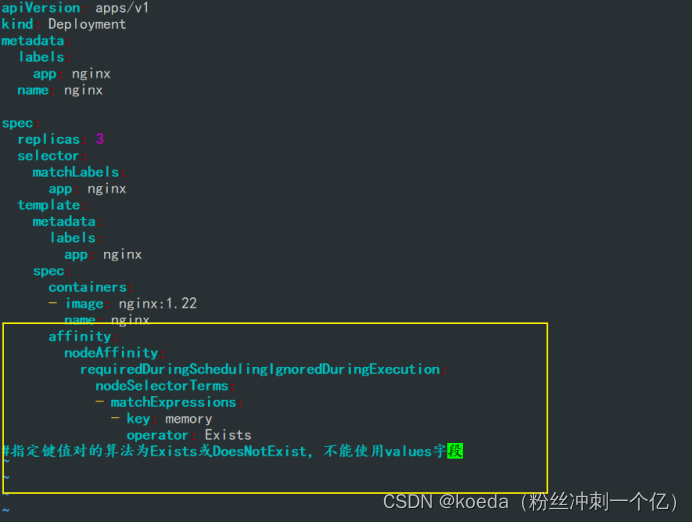 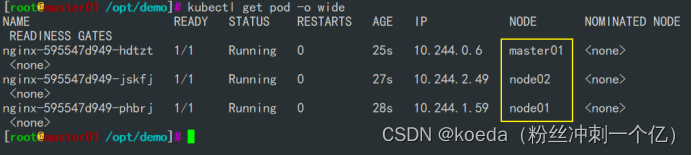 ****DoesNotExist:**** 1. `affinity:` 2. `nodeAffinity:` 3. `requiredDuringSchedulingIgnoredDuringExecution:` 4. `nodeSelectorTerms:` 5. `- matchExpressions:` 6. `- key: memory` 7. `operator: DoesNotExist` 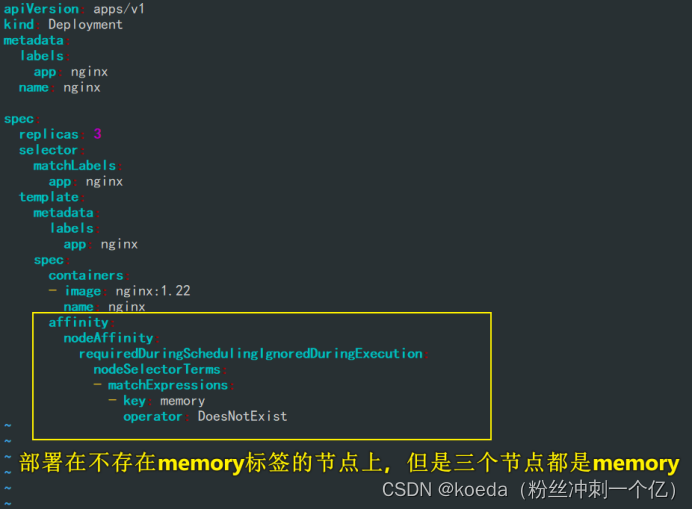 ****软策略:**** 1. `affinity:` 2. `nodeAffinity:` 3. `preferredDuringSchedulingIgnoredDuringExecution:` 4. `- weight: 1` 5. `preference:` 6. `matchExpressions:` 7. `- key: memory` 8. `operator: In` 9. `values:` 10. `- "1000"` 12. `preferredDuringSchedulingIgnoredDuringExecution:` 13. `- weight: 10` 14. `preference:` 15. `matchExpressions:` 16. `- key: memory` 17. `operator: In` 18. `values:` 19. `- "500"` 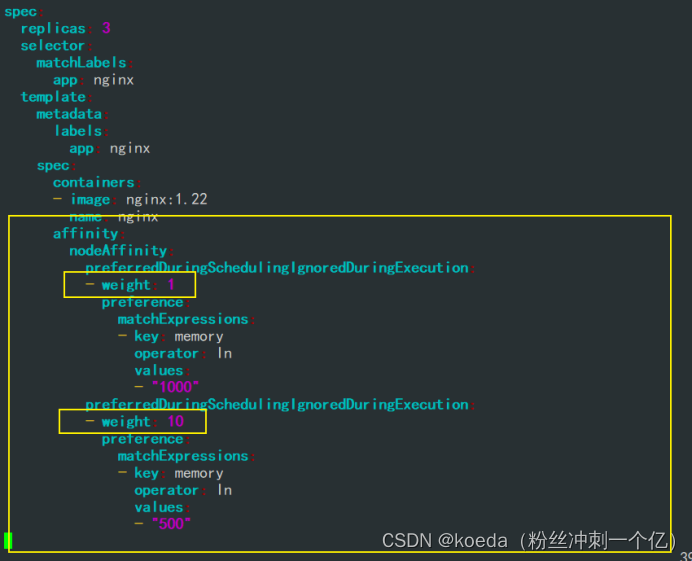 多个软策略看权重,权重高,执行指定的软策略 硬策略和软策略一起执行: 先满足硬策略,再考虑软策略。若硬策略无法满足,软策略一个都不会执行 ****面试题:**** 你在部署pod的时候选择什么样的策略: 根据node的亲和性: 性能不一致,尽量把pod往性能高的多部署,选择软策略 节点故障或者节点维护中,只能选择硬策略,把故障节点剔除 ##### 4、pod亲和性实例 ###### ****4.1、pod的亲和性和反亲和性:**** <table><tbody><tr><td><p>调度策略:</p></td><td><p>匹配标签</p></td><td><p>操作符</p></td><td><p>拓扑域</p></td><td><p>调度目标</p></td></tr><tr><td><p>node的亲和性</p></td><td><p>主机标签</p></td><td><p>In、NotIn、Exists、DoesNotExist、Gt、Lt</p></td><td><p>不支持</p></td><td><p>指定主机</p></td></tr><tr><td><p>pod的亲和性</p></td><td><p>pod的标签</p></td><td><p>In、NotIn、Exists、DoesNotExist</p></td><td><p>支持</p></td><td><p>pod和指定标签的pod部署在同一个拓扑域</p></td></tr><tr><td><p>pod的反亲和性</p></td><td><p>pod的标签</p></td><td><p>In、NotIn、Exists、DoesNotExist</p></td><td><p>支持</p></td><td><p>pod和指定标签的pod部署在不同一个拓扑域</p></td></tr></tbody></table> ###### ****4.2、拓扑域:**** K8S集群节点当中的一个组织结构,可以根据节点的物理关系或者逻辑关系进行划分 可以用来标识节点之间的空间关系,网络关系,或者其他类型的关系 这里pod的亲和性的拓扑域是标签 ###### ****4.3、pod的亲和性实例:**** ****1、In**** > 1. `apiVersion: apps/v1` > > 2. `kind: Deployment` > > 3. `metadata:` > > 4. `labels:` > > 5. `app: nginx` > > 6. `name: nginx` > > > 8. `spec:` > > 9. `replicas: 3` > > 10. `selector:` > > 11. `matchLabels:` > > 12. `app: nginx` > > 13. `template:` > > 14. `metadata:` > > 15. `labels:` > > 16. `app: nginx` > > 17. `spec:` > > 18. `containers:` > > 19. `- image: nginx:1.22` > > 20. `name: nginx` > > 21. `affinity:` > > 22. `podAffinity:` > > 23. `requiredDuringSchedulingIgnoredDuringExecution:` > > 24. `- labelSelector:` > > 25. `matchExpressions:` > > 26. `- key: app` > > 27. `operator: In` > > 28. `values:` > > 29. `- nginx` > > 30. `topologyKey: test1` > > 31. `#topologyKey指定拓扑域的关键字段,表示正在使用test1作为拓扑的关键字。test1一般是节点标签,表示希望吧pod调度到包含有app标签的pod,值为nginx1的在test1的拓扑域上的节点` >  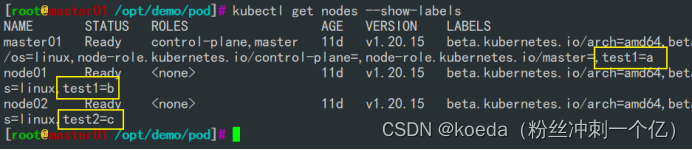  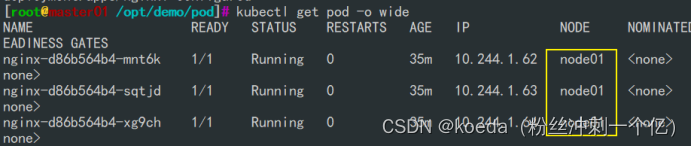 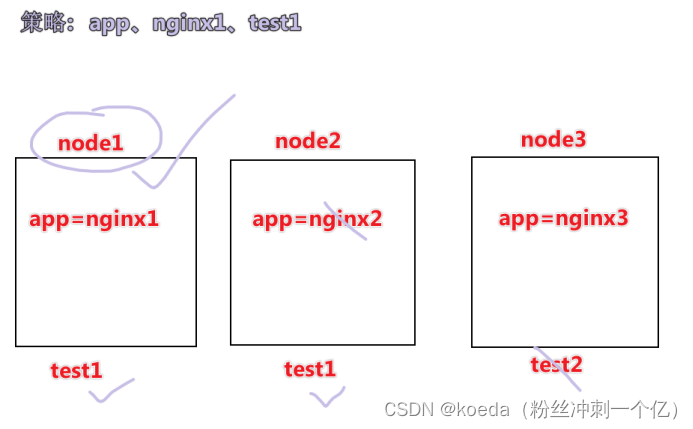 ****2、Exists**** 满足test1节点,且满足pod标签等于app的 1. `affinity:` 2. `podAffinity:` 3. `requiredDuringSchedulingIgnoredDuringExecution:` 4. `- labelSelector:` 5. `matchExpressions:` 6. `- key: app` 7. `operator: Exists` 8. `topologyKey: test1`  ****软策略:**** 表示尽量选择满足不存在app的pod标签的 并且 是满足test1的节点的 > 1. `affinity:` > > 2. `podAffinity:` > > 3. `preferredDuringSchedulingIgnoredDuringExecution:` > > 4. `- weight: 1` > > 5. `podAffinityTerm:` > > 6. `labelSelector:` > > 7. `matchExpressions:` > > 8. `- key: app` > > 9. `operator: DoesNotExist` > > 10. `topologyKey: test1` >  ****反亲和性:**** 表示反转,满足哪个就不去哪个 软策略反亲和性:   硬策略反亲和性:  ****注意点:**** 1. pod的亲和性策略,在配置时,必须要加上拓扑域的关键字topologykey,指向的是节点标签 2. pod亲和性的策略分为硬策略和软策略 3. pod亲和性的NotIn可以替代反亲和性 4. ****pod亲和性主要是为了把相关联的pod组件部署在同一节点上。lnmp**** 你在进行部署的时候,怎么考虑node节点: 软硬策略 污点和容忍 污点和容忍可以配合node的亲和性一块使用 污点:是node的调度机制,不是pod 被设为污点的节点,不会部署pod 污点和亲和性相反,亲和性是尽量选择和一定选择 污点的节点一定不被选择? 一、污点 1.查看主节点污点:kubectl describe nodes master 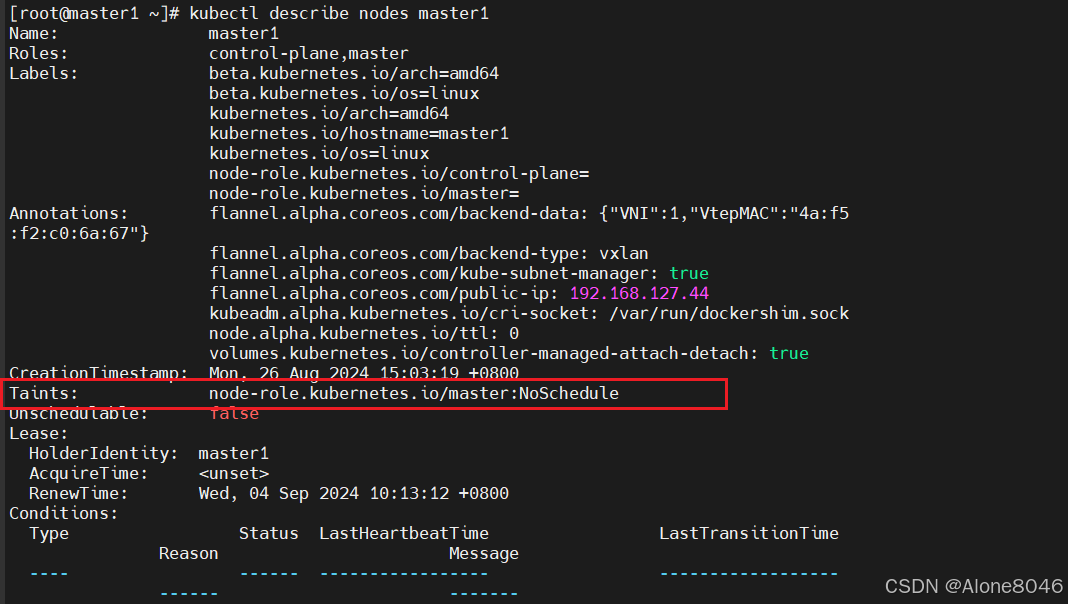 2.污点是什么:一旦节点上有污点的标签,那么调度器在部署pod的时候会避开这些有污点标签的节点。 3.污点的两种格式: 1》key:effect 键值:类型 kubectl taint node node1 test1:effect 2》key=value:effect 键值=值:类型 kubectl taint node node1 test1=1:effect  3.污点的类型: 1》NoSchedule:节点上一旦有这个污点,调度器不会把pod部署到该节点上。 2》PreferNoSchedule:尽量避免把pod部署到该节点。 3》NoExecute:调度器不仅不会把pod部署到该节点,而且会把该节点的pod驱逐到其它节点上。 4.删除污点:  三种污点类型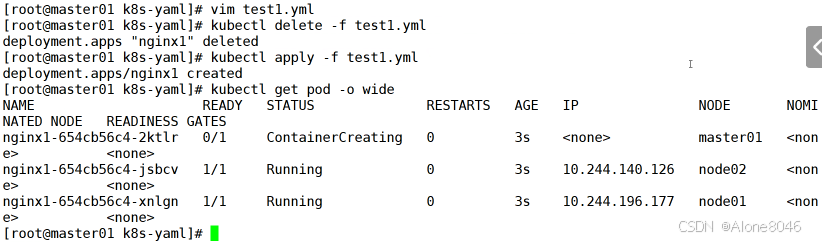 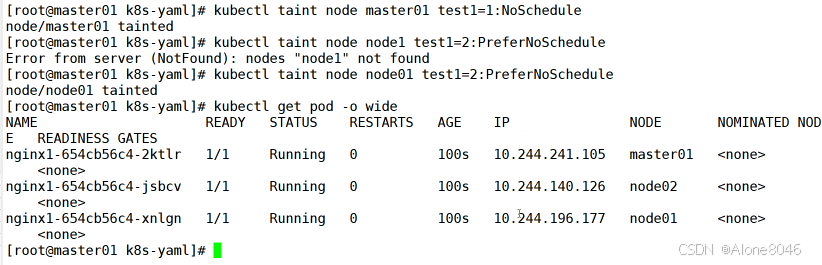 修改污点类型  二、容忍:k8s第二个机制 1.容忍:即使节点上有污点,调度依然可以把pod部署在有污点的节点上。 2.容忍的类型只有两个 operator: Equal(等于)和Exists(包含) Equal类型 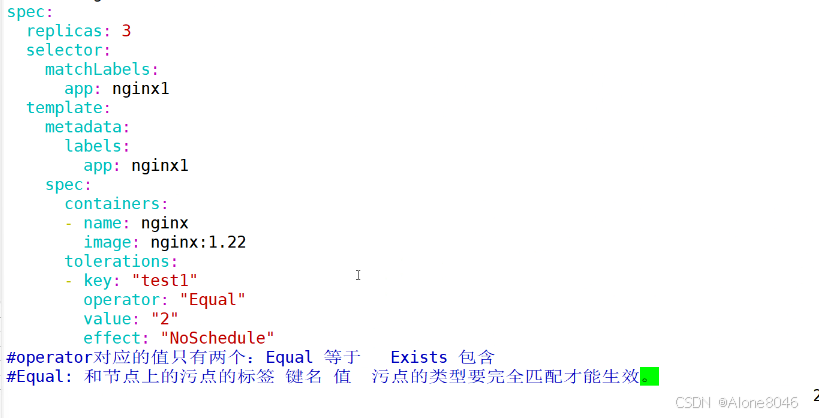 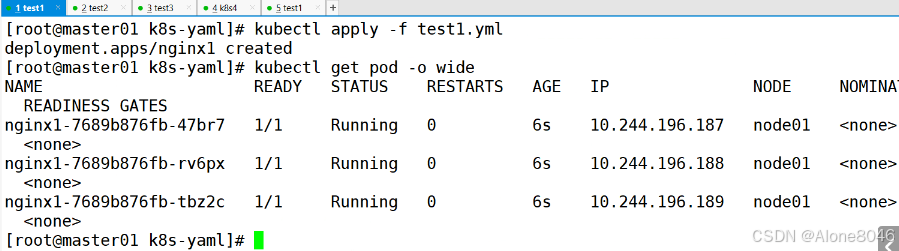 污点的容忍类型为驱逐NoExecute tolerationseconds只能和Equal一起使用   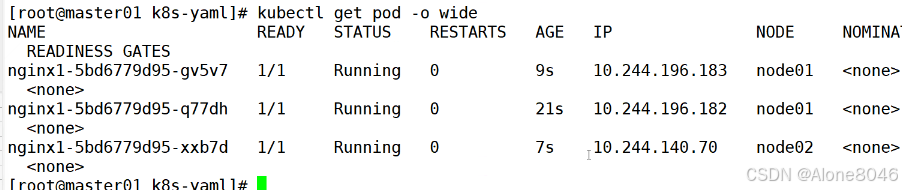 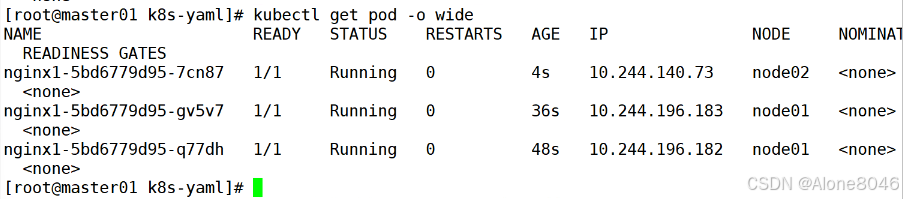 Exists类型 只要是指定污点,不管节点key键值是啥都会部署  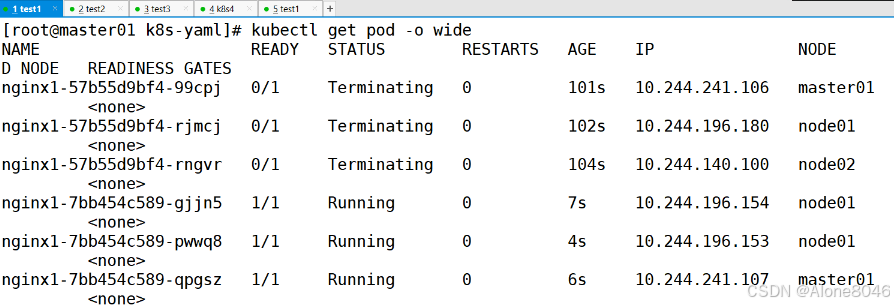 只要键值key存在,不考虑你是啥污点类型都会部署   三、cordon不可调度:直接标记节点为不可用节点 kubectl cordon node1  四、drain排水(谨慎使用):标记节点为不可调度,而且会把节点上的pod驱逐到其它节点 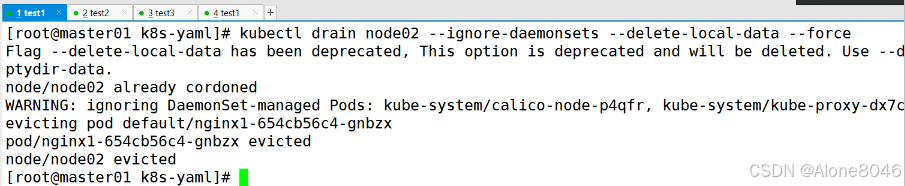 \--ignore:无视daemonsets的部署的pod \-data:如果被排水的节点上有本地的挂载点,会强制杀死 \--force:不是控制器创建的pod会被强制释放   如何恢复 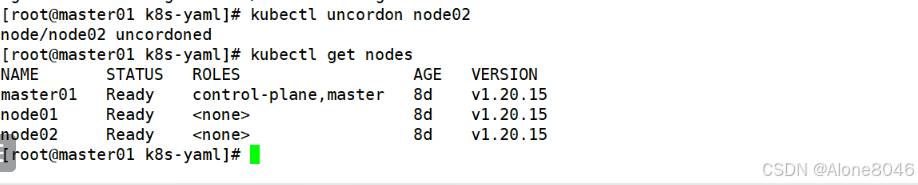 五、面试题 问:当排水和驱逐之后,怎么样能让pod重新回到节点? 回:污点类型放逐必须要取消 kubectl uncordon node1 重启 delete -f 六、关于主节点master一般情况下做为集群的调度器,尽量不部署pod,但是为了资源最大化,master也可以部署,前提是设置污点类型为preferNoschedule;如果集群规模很小,可以直接用来当节点部署。 七、数据卷volum pod的生命周期是有限的,一旦重启或者崩溃数据就会丢失,为了保证数据的完整,我们要实现pod内的容器和节点进行挂载 1.数据卷类型: emptyDir存储卷:容器和容器之间挂载;pod分配给节点之前,首先创建emotyDir卷,只要运行在节点,数据卷就会一直存在;这个数据卷不能和宿主机共享,pod内容器之间共享,一旦pod重启,enptyDir卷的数据也会一起删除。主要用于容器内部组件通信,不涉及敏感数据。 hostPath数据卷:每个pod和节点进行挂载,当pod部署到节点时,就会和节点的指定目录进行挂载;数据可以持久化;node节点数据格式化pod数据也就会消失。每个pod运行的数据不同,保留的数据要做分区,所以需要hostPath挂载。 Nfs共享存储卷:整个k8s集群里的pod相当于客户端,另外一台服务器提供Nfs共享;也就是所有pod共享一个挂载点,所有的数据也都在这一个挂载点。用于nginx服务或者pod的数据是一致的。 2.实验: 1》emptyDir:用{}代表 容器1的user/share和容器2 data/目录进行挂载,数据卷类型为emptyDir 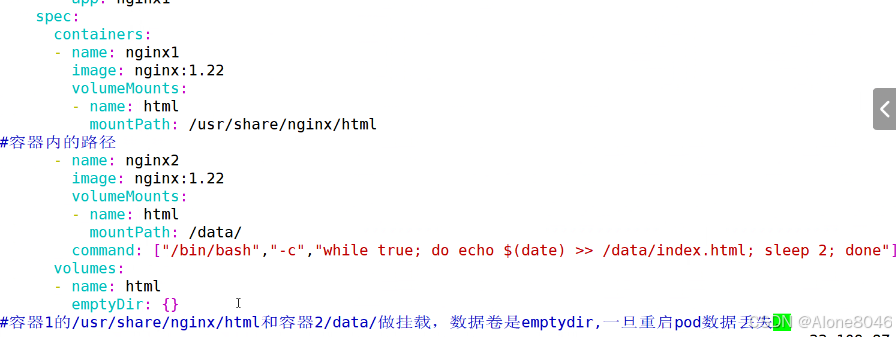 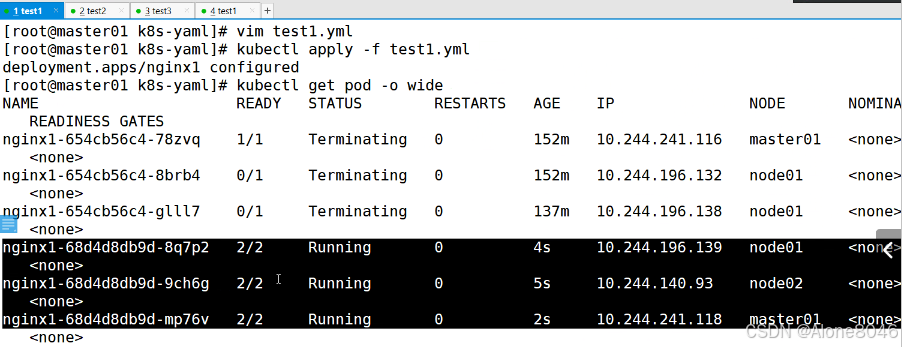 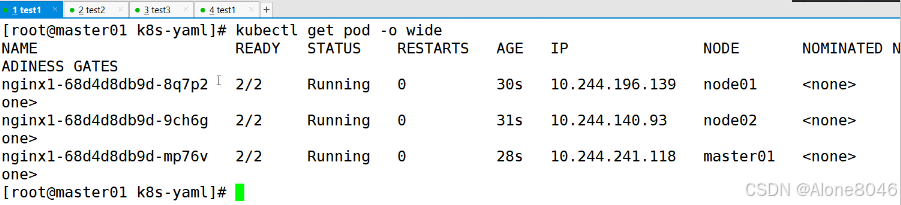  进入pod其中一个容器内  2》hostPath数据卷实验 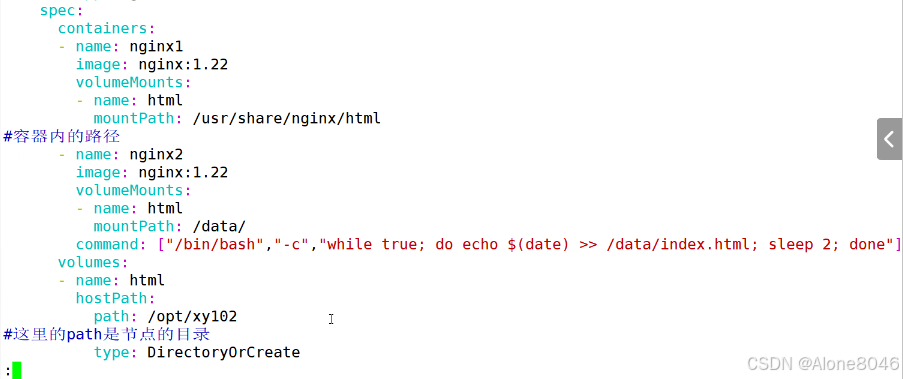 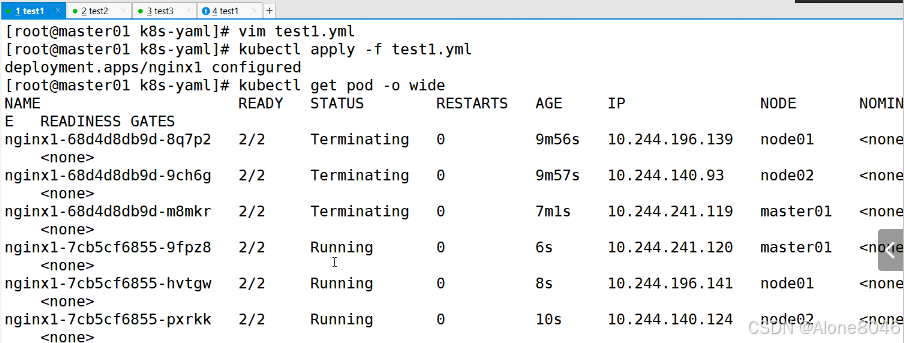 三台共同操作:以节点的数据为主  3》Nfs共享存储卷实验 K8s集群: 192.168.127.44 master1 192.168.127.55 node1 192.168.127.66 node2 192.168.127.36 集群外主机 首先四台主机做IP--主机名的映射  集群外主机创建目录 mkdir /opt/data1  在k8s主节点yaml文件内进行nfs挂载  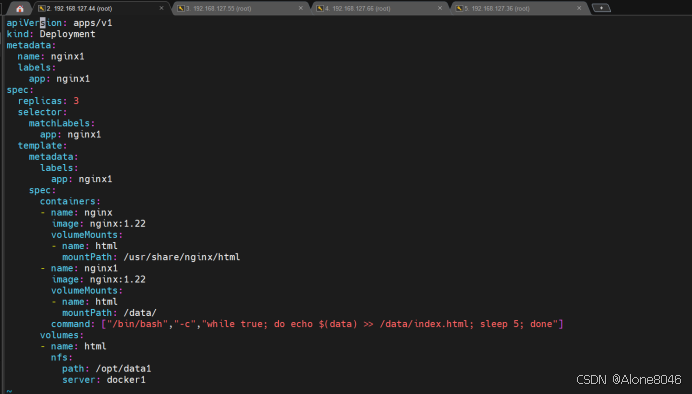 于集群外主机创建的data1目录下创建文件并查看挂载结果 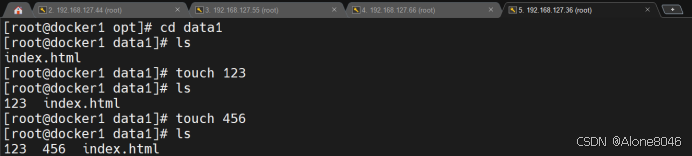 查看容器内挂载情况 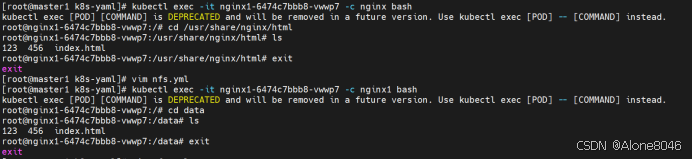
adouk
2024年11月19日 14:17
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码