系统监控
奥科sbc监控简易说明-v9
Prometheus与SNMP对接监控
zabbix5.2批量监控laihu3.0指定端口
prometheus监控说明
prometheus监控服务端口状态
Prometheus监控运维实战十: 主机监控指标
prometheus 使用 ipmi exporter 增加硬件级别监控
jvm监控指标 - 求其在我 - 博客园
nginx_exporter的安装
Nginx Exporter 接入
CentOS 7下Nginx安装配置nginx-module-exporter 数据采集器 - 灰信网(软件开发博客聚合)
Zabbix统一监控系统
奥科sbc监控说明-v6
AlertManager告警服务
Prometheus AlertManager讲解
CentOS安装snmp-exporter部署来监控cisco交换机端口
prometheus监控之Domain域名过期监控
监控群晖NAS
linux下docker搭建Prometheus +SNMP Exporter +Grafana进行核心路由器交换机监控
ES8生产实践——数据查询与数据可视化(Grafana)
本文档使用 MrDoc 发布
-
+
首页
AlertManager告警服务
```bash Altermanager是Prometheus中的一个独立的告警模块,主要是用针对异常数据进行报警。首先创建一个报警的规则,其次创建路由(给谁发报警信息)。 ``` 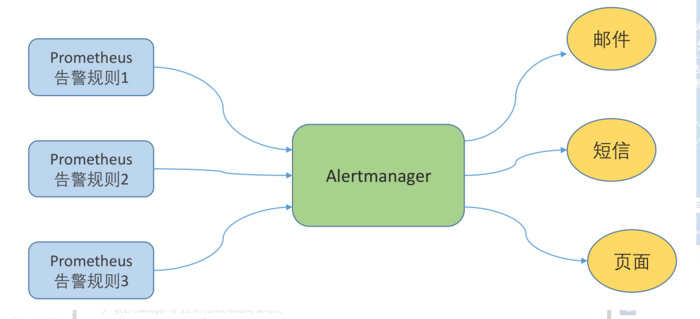 ### 二、部署方式 ```bash alertManager部署有两种方式: #1、容器化部署 #2、安装包部署 ``` ### 三、容器化部署 ```yaml apiVersion: monitoring.coreos.com/v1 kind: Alertmanager metadata: labels: alertmanager: main name: main namespace: monitoring spec: image: quay.io/prometheus/alertmanager:v0.20.0 nodeSelector: kubernetes.io/os: linux replicas: 3 securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 serviceAccountName: alertmanager-main version: v0.20.0 ``` ```bash [root@kubernetes-master-01 manifests]# kubectl get pod -n monitoring NAME READY STATUS RESTARTS AGE alertmanager-main-0 2/2 Running 0 4d23h alertmanager-main-1 2/2 Running 0 4d23h alertmanager-main-2 2/2 Running 0 4d23h ``` ```yaml kind: Ingress apiVersion: extensions/v1beta1 metadata: name: alertmanager namespace: monitoring spec: rules: - host: "www.altermanager.cluster.local.com" http: paths: - backend: serviceName: alertmanager-main servicePort: 9093 path: / ``` ### 四、安装包部署 ### 1.下载altermanager组件 ```bash #下载altermanager组件 [root@ga002 ~]# cd /opt [root@ga002 opt]# wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz ``` ### 2.解压altermanager组件 ```bash #解压altermanager组件 [root@ga002 opt]# tar -xf alertmanager-0.21.0.linux-amd64.tar.gz ``` ### 3.建立alertManager报警规则 ```bash #1.建立alertManager报警规则 [root@ga002 opt]# cd alertmanager-0.21.0.linux-amd64 [root@ga002 alertmanager-0.21.0.linux-amd64]# ll total 51644 -rwxr-xr-x 1 3434 3434 28871879 Jun 17 2020 alertmanager -rw-r--r-- 1 3434 3434 380 Jun 17 2020 alertmanager.yml -rwxr-xr-x 1 3434 3434 23987848 Jun 17 2020 amtool -rw-r--r-- 1 3434 3434 11357 Jun 17 2020 LICENSE -rw-r--r-- 1 3434 3434 457 Jun 17 2020 NOTICE [root@ga002 alertmanager-0.21.0.linux-amd64]# vim alertmanager.yml global: resolve_timeout: 1h # 警告的间隔时间,默认是:5m # 邮件告警配置 smtp_smarthost: 'smtp.mxhichina.com:465' smtp_from: 'smtp.mxhichina.com' smtp_auth_username: 'mjn.support@DataXgroup.com' smtp_auth_password: '**********' smtp_require_tls: true # 配置报警的模板 templates: - '/etc/alertmanager/config/*.tmpl' # 路由 route: # 匹配的标签的ksy group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 4h receiver: 'email' routes: - receiver: 'email' match_re: # 匹配的是标签的值 service: '^(warning|critical)$' # 接收者 receivers: - name: 'email' email_configs: - to: 'li.yang@dataxgroup.com,hui.jin@dataxgroup.com' send_resolved: true #2.检查配置是否生效 [root@ga002 alertmanager-0.21.0.linux-amd64]# ./amtool check-config alertmanager.yml Checking 'alertmanager.yml' SUCCESS Found: - global config - route - 0 inhibit rules - 1 receivers - 1 templates SUCCESS ``` ### 4.新建告警规则文件夹 ```bash [root@ga002 alertmanager-0.21.0.linux-amd64]# mkdir /etc/alertmanager/config/ -p ``` ### 5.规则具体概述 ```yaml global: resolve_timeout: 1h # 警告的间隔时间,默认是:5m # 邮件告警配置 smtp_smarthost: 'smtp.qq.com:465' smtp_from: 'axxxy@qq.com' smtp_auth_username: 'axxxy@qq.com' smtp_auth_password: 'qxxxxb' smtp_require_tls: false # 配置报警的模板 templates: - '/etc/alertmanager/config/*.tmpl' # 路由 route: # 匹配的标签的ksy group_by: ['severity'] group_wait: 30s group_interval: 5m repeat_interval: 4h receiver: 'email' routes: - receiver: 'email' match_re: # 匹配的是标签的值 service: '^(warning|critical)$' # 接收者 receivers: - name: 'email' email_configs: - to: '12xxxx30@qq.com' send_resolved: true ``` ### 6.邮件告警模板 ```bash [root@ga002 alertmanager-0.21.0.linux-amd64]# vim /etc/alertmanager/config/email.tmpl ``` ```bash {{ define "email.to.html" }} {{ range .Alerts }} =========start==========<br> 告警程序: prometheus_alert <br> 告警级别: {{ .Labels.severity }} <br> 告警类型: {{ .Labels.alertname }} <br> 故障主机: {{ .Labels.instance }} <br> 告警主题: {{ .Annotations.summary }} <br> 告警详情: {{ .Annotations.description }} <br> =========end==========<br> {{ end }} {{ end }} ``` ### 7.配置system启动 ```bash #1.创建相关数据存放目录 [root@ga002 alertmanager-0.21.0.linux-amd64]# mkdir /data/alertmanager/medate/ -p #2.配置system启动 [root@ga002 alertmanager-0.21.0.linux-amd64]# vim /etc/systemd/system/alertmanager.service [Unit] Description=alertmanager Documentation=https://prometheus.io/ After=network.target [Service] Type=simple User=root ExecStart=/opt/alertmanager-0.21.0.linux-amd64/alertmanager --config.file=/opt/alertmanager-0.21.0.linux-amd64/alertmanager.yml --storage.path=/data/alertmanager/medate/ --data.retention=120h Restart=on-failure [Install] WantedBy=multi-user.target 或者直接启动 [root@ga002 opt]# nohup /opt/alertmanager-0.21.0.linux-amd64/alertmanager --config.file="/opt/alertmanager-0.21.0.linux-amd64/alertmanager.yml" --storage.path="/data/alertmanager/medate/" --data.retention=60h & #3.启动服务 [root@ga002 opt]# systemctl daemon-reload [root@ga002 opt]# systemctl enable --now alertmanager ``` ### 8.**Alertmanager 参数** | 参数 | 描述 | | --- | --- | | `--config.file="alertmanager.yml"` | 指定Alertmanager配置文件路径 | | `--storage.path="data/"` | Alertmanager的数据存放目录 | | `--data.retention=120h` | 历史数据保留时间,默认为120h | | `--alerts.gc-interval=30m` | 警报gc之间的间隔 | | `--web.external-url=WEB.EXTERNAL-URL` | 外部可访问的Alertmanager的URL(例如Alertmanager是通过nginx反向代理) | | `--web.route-prefix=WEB.ROUTE-PREFIX` | wen访问内部路由路径,默认是 `--web.external-url` | | `--web.listen-address=":9093"` | 监听端口,可以随意修改 | | `--web.get-concurrency=0` | 并发处理的最大GET请求数,默认为0 | | `--web.timeout=0` | web请求超时时间 | | `--cluster.listen-address="0.0.0.0:9094"` | 集群的监听端口地址。设置为空字符串禁用HA模式 | | `--cluster.advertise-address=CLUSTER.ADVERTISE-ADDRESS` | 配置集群通知地址 | | `--cluster.gossip-interval=200ms` | 发送条消息之间的间隔,可以以增加带宽为代价更快地跨集群传播。 | | `--cluster.peer-timeout=15s` | 在同级之间等待发送通知的时间 | | … | … | | `--log.level=info` | 自定义消息格式 \[debug, info, warn, error\] | | `--log.format=logfmt` | 日志消息的输出格式: \[logfmt, json\] | | `--version` | 显示版本号 | ### 9.验证服务 ```bash [root@ga002 alertmanager-0.21.0.linux-amd64]# systemctl status alertmanager.service ● alertmanager.service - alertmanager Loaded: loaded (/etc/systemd/system/alertmanager.service; enabled; vendor preset: disabled) Active: active (running) since Mon 2021-05-17 14:39:41 CST; 2s ago Docs: https://prometheus.io/ Main PID: 20482 (alertmanager) CGroup: /system.slice/alertmanager.service └─20482 /opt/alertmanager-0.21.0.linux-amd64/alertmanager --config.file=/opt/alertmanager-0.21.0.linux-amd64/alertmanager.yml --storage.path=/data/alertmanager/medate/ --data.retention=120h May 17 14:39:41 ga002 systemd[1]: Started alertmanager. May 17 14:39:41 ga002 alertmanager[20482]: level=info ts=2021-05-17T06:39:41.655Z caller=main.go:216 msg="Starting Alertmanager" version="(version=0.21.0, branch=HEAD, revision=4c6c03ebfe21009c546...c371d67c021d)" May 17 14:39:41 ga002 alertmanager[20482]: level=info ts=2021-05-17T06:39:41.655Z caller=main.go:217 build_context="(go=go1.14.4, user=root@dee35927357f, date=20200617-08:54:02)" May 17 14:39:41 ga002 alertmanager[20482]: level=info ts=2021-05-17T06:39:41.656Z caller=cluster.go:161 component=cluster msg="setting advertise address explicitly" addr=172.19.90.51 port=9094 May 17 14:39:41 ga002 alertmanager[20482]: level=info ts=2021-05-17T06:39:41.657Z caller=cluster.go:623 component=cluster msg="Waiting for gossip to settle..." interval=2s May 17 14:39:41 ga002 alertmanager[20482]: level=info ts=2021-05-17T06:39:41.678Z caller=coordinator.go:119 component=configuration msg="Loading configuration file" file=/opt/alertmanager-0.21.0.l...ertmanager.yml May 17 14:39:41 ga002 alertmanager[20482]: level=info ts=2021-05-17T06:39:41.678Z caller=coordinator.go:131 component=configuration msg="Completed loading of configuration file" file=/opt/alertman...ertmanager.yml May 17 14:39:41 ga002 alertmanager[20482]: level=info ts=2021-05-17T06:39:41.682Z caller=main.go:485 msg=Listening address=:9093 May 17 14:39:43 ga002 alertmanager[20482]: level=info ts=2021-05-17T06:39:43.657Z caller=cluster.go:648 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.000073812s Hint: Some lines were ellipsized, use -l to show in full. ```  ### 五、配置promethus ```bash #1.进入promethus配置目录 [root@ga002 opt]# cd /opt/prometheus-2.17.1.linux-amd64/ #2.修改promethus配置文件 [root@ga002 prometheus-2.17.1.linux-amd64]# vim prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: ['ga002:9093'] # - alertmanager: 9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "rule.yml" # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['ga002:9090'] - job_name: 'node_exporter' metrics_path: /metrics static_configs: - targets: ['ga002:9100','gd001:9100','ga001:9100','gw001:9100','ga003:9100'] - job_name: 'mysql_exporter' metrics_path: /metrics static_configs: - targets: ['gd001:9104'] labels: instance: gatorade - job_name: 'alertmanger' static_configs: - targets: ['ga002:9093'] #3.添加promethus规则文件 [root@ga002 config]# vim /opt/prometheus-2.17.1.linux-amd64/rule.yml groups: - name: alertname rules: - alert: InstanceDown expr: up == 0 for: 2m labels: status: warning annotations: summary: "{{$labels.instance}}: has been down" description: "{{$labels.instance}}: job {{$labels.job}} has been down" - name: base-monitor-rule rules: - alert: NodeCpuUsage expr: (100 - (avg by (instance) (rate(node_cpu{job=~".*",mode="idle"}[2m])) * 100)) > 99 for: 15m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: CPU usage is above 99% (current value is: {{ $value }}" - alert: NodeMemUsage expr: avg by (instance) ((1- (node_memory_MemFree{} + node_memory_Buffers{} + node_memory_Cached{})/node_memory_MemTotal{}) * 100) > 90 for: 15m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: MEM usage is above 90% (current value is: {{ $value }}" - alert: NodeDiskUsage expr: (1 - node_filesystem_free{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size) * 100 > 80 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Disk usage is above 80% (current value is: {{ $value }}" - alert: NodeFDUsage expr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 80 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: File Descriptor usage is above 80% (current value is: {{ $value }}" - alert: NodeLoad15 expr: avg by (instance) (node_load15{}) > 100 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Load15 is above 100 (current value is: {{ $value }}" # - alert: NodeAgentStatus # expr: avg by (instance) (up{}) == 0 # for: 2m # labels: # service_name: test # level: warning # annotations: # description: "{{$labels.instance}}: Node Agent is down (current value is: {{ $value }}" - alert: NodeProcsBlocked expr: avg by (instance) (node_procs_blocked{}) > 100 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Blocked Procs detected!(current value is: {{ $value }}" - alert: NodeTransmitRate expr: avg by (instance) (floor(irate(node_network_transmit_bytes{device="eth0"}[2m]) / 1024 / 1024)) > 100 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Transmit Rate is above 100MB/s (current value is: {{ $value }}" - alert: NodeReceiveRate expr: avg by (instance) (floor(irate(node_network_receive_bytes{device="eth0"}[2m]) / 1024 / 1024)) > 100 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Receive Rate is above 100MB/s (current value is: {{ $value }}" - alert: NodeDiskReadRate expr: avg by (instance) (floor(irate(node_disk_bytes_read{}[2m]) / 1024 / 1024)) > 50 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Disk Read Rate is above 50MB/s (current value is: {{ $value }}" - alert: NodeDiskWriteRate expr: avg by (instance) (floor(irate(node_disk_bytes_written{}[2m]) / 1024 / 1024)) > 50 for: 2m labels: service_name: test level: warning annotations: description: "{{$labels.instance}}: Node Disk Write Rate is above 50MB/s (current value is: {{ $value }}" #4.重启相关服务 [root@ga002 ~]# systemctl restart alertmanager.service [root@ga002 ~]# systemctl status alertmanager.service [root@ga002 ~]# systemctl restart prometheus.service ``` ### 六、验证服务 ### 1.关闭node\_exporter服务 ```bash [root@ga002 config]# systemctl stop node_exporter.service ``` ### 2.查看服务器监控状态 ```bash 当状态从Pending转为Firing,此时邮件就会发送 ``` 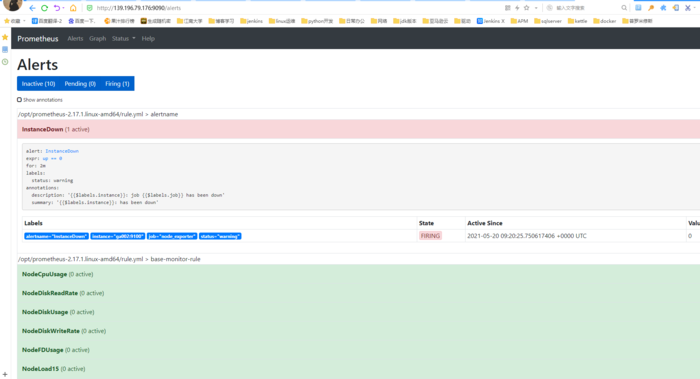 ### 3.查看邮件信息 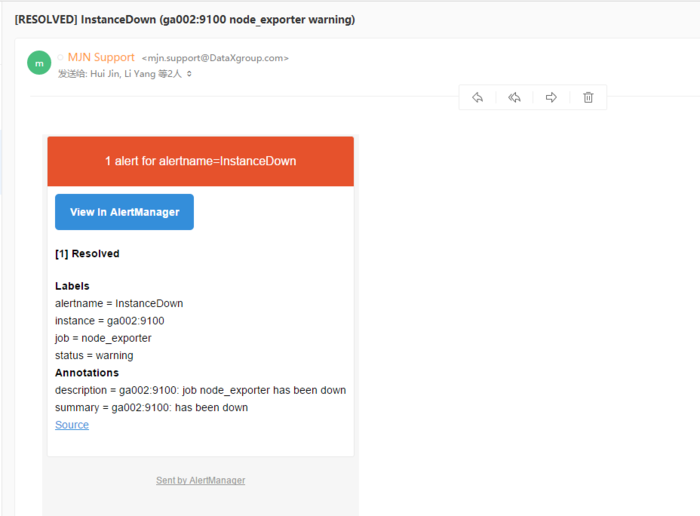 ### 4.重启node\_exporter服务 ```bash [root@ga002 config]# systemctl start node_exporter.service ``` ### 5.查看服务器监控状态 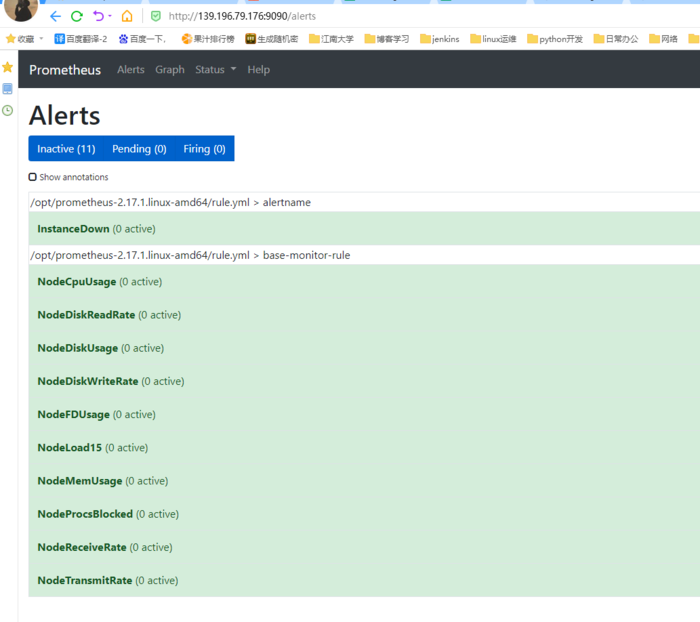 ### 6.查看邮件信息 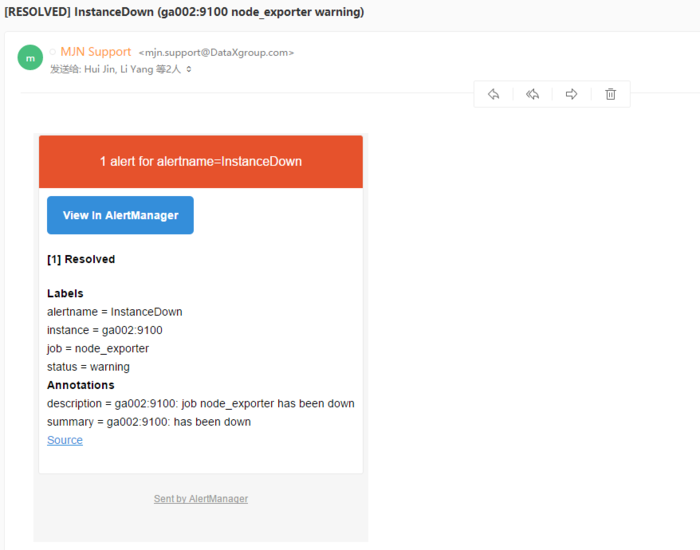
adouk
2023年4月24日 09:35
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码